Home » U++ Library support » U++ Core » Writing Bits object to disk
|
|
| Re: Writing Bits object to disk [message #47960 is a reply to message #47952] |
Thu, 27 April 2017 10:31   |
 crydev
crydev
Messages: 151
Registered: October 2012
Location: Netherlands
|
Experienced Member |
|
|
Thanks Mirek!
I have been trying a thing or two myself. I wrote a version of the Set(int, bool) method that accepts four bool values at the same time. This version _probably_ has more pipelining capabilities, and is faster than the regular set method!
union BitBoolPipeline
{
struct
{
bool b1;
bool b2;
bool b3;
bool b4;
};
dword dw;
};
// Different function implementing Bits, but with a pipelined set method.
const int VectorBoolOrBitsetTestBitSetPipeline(Bits& buffer, const Vector<bool>& rand)
{
const int count = rand.GetCount();
for (int i = 0; i < count; i += 4)
{
// We can now set four bools at the same time. However, we must assume that a bool that
// is set to true has value 0x1, and a bool set to false has value 0x0.
BitBoolPipeline b;
b.b1 = rand[i];
b.b2 = rand[i + 1];
b.b3 = rand[i + 2];
b.b4 = rand[i + 3];
buffer.PipelineSet(i, b.dw);
}
int alloc = 0;
buffer.Raw(alloc);
return alloc;
}
const dword PowersOfTwo[] =
{
0x1, 0x2, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80, 0x100, 0x200, 0x400, 0x800, 0x1000, 0x2000,
0x4000, 0x8000, 0x10000, 0x20000, 0x40000, 0x80000, 0x100000, 0x200000, 0x400000, 0x800000,
0x1000000, 0x2000000, 0x4000000, 0x8000000, 0x10000000, 0x20000000, 0x40000000, 0x80000000
};
// Testing pipelined version of Bits::Set(int, bool)
void Bits::PipelineSet(int i, const dword bs)
{
// Check whether i is within the bounds of the container.
ASSERT(i >= 0 && alloc >= 0);
// Get the DWORD index for the internal buffer.
int q = i >> 5;
// Get the bit index of the next available DWORD.
i &= 31;
// Do we need to expand the internal buffer first?
// Also check whether we can place 4 bits in the existing DWORD. If not, we should expand.
if(q >= alloc)
Expand(q);
// Get integer bit values according to existing DWORD value and indices.
// Assuming default value of bool is 0x1 if true!
bp[q] = (bp[q] | bs & PowersOfTwo[1] | bs & PowersOfTwo[8] | bs & PowersOfTwo[16] | bs & PowersOfTwo[24]);
}
This function assumes that a bool set to true has value 0x1, and 0x0 otherwise. I made the array of constant powers of two in advance. Replacing the array indices with the array constant itself doesn't improve any further, because the compiler propagates the constants by itself. The measurement is as follows:
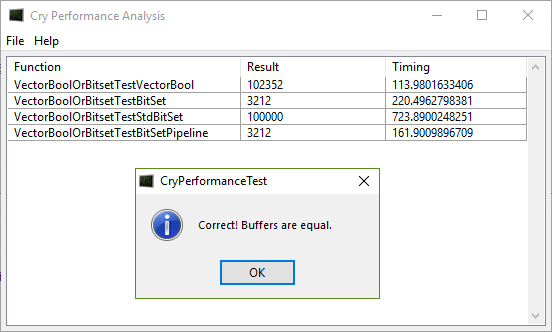
I'm also working on a SIMD version that should be able to set 16 bools in parallel, having some assumptions about the input. 
crydev
-
 Attachment: Capture.PNG
Attachment: Capture.PNG
(Size: 17.25KB, Downloaded 751 times)
[Updated on: Thu, 27 April 2017 10:33] Report message to a moderator |
|
|
|
| Re: Writing Bits object to disk [message #47963 is a reply to message #47960] |
Thu, 27 April 2017 23:50 |
 |
mirek
Messages: 14285
Registered: November 2005
|
Ultimate Member |
|
|
Problem with this approach is that you have to create intput Vector<bool> argument first, which is likely to spoil any benefits from faster Bits...
Really, this is the issue - to improve speed here, the interface is problem.
Some possible solutions that came to my mind:
void Bits::Set(int pos, int count, dword bits);
Here count <= 32 and you are passing values in bits dword; that would work if you are packing some normal data into Bits.
template
void Bits::Set(int pos, int count, auto lambda /* [=] (int pos) -> bool */)
Here we would provide lambda that returns value for given position - if compiler is good, it should inline well.
tempalte
void Bits::Set(int pos, bool x ...)
Maybe vararg template is a possible solution to the problem too.
Now the question is: How are you using Bits?
Mirek
|
|
|
|
| Re: Writing Bits object to disk [message #47964 is a reply to message #47963] |
Fri, 28 April 2017 19:04 |
crydev
Messages: 151
Registered: October 2012
Location: Netherlands
|
Experienced Member |
|
|
mirek wrote on Thu, 27 April 2017 23:50Problem with this approach is that you have to create intput Vector<bool> argument first, which is likely to spoil any benefits from faster Bits...
Really, this is the issue - to improve speed here, the interface is problem.
Some possible solutions that came to my mind:
void Bits::Set(int pos, int count, dword bits);
Here count <= 32 and you are passing values in bits dword; that would work if you are packing some normal data into Bits.
template
void Bits::Set(int pos, int count, auto lambda /* [=] (int pos) -> bool */)
Here we would provide lambda that returns value for given position - if compiler is good, it should inline well.
tempalte
void Bits::Set(int pos, bool x ...)
Maybe vararg template is a possible solution to the problem too.
Now the question is: How are you using Bits?
Mirek
Thanks Mirek,
I am building a memory scanner. The results of this scanner consist of a set of addresses and a set of corresponding values. The addresses are fairly well structured. That is: they live in pages, and always live at a specific offset from a base address. Therefore, I can efficiently store this data by using Bits. Every bit is an address, and I keep track of the metadata like base address and offsets. However, that means that I have to write billions of bits to the Bits structure. Therefore, my application benefits from vectorized approaches of setting.
Having to create an input vector of bools may not be very efficient, but it is more efficient in my test case. Moreover, it is also a nice solution to have a Bits::Set method do this in another way, not having to do it yourself.
I understand that vectorized versions of the Bits::Set function are not portable and should not be in U++ for portability reasons, but instruction pipelining is available on many architectures. I think it can be well exploited in this case!
crydev
[Updated on: Fri, 28 April 2017 19:05] Report message to a moderator |
|
|
|
| Re: Writing Bits object to disk [message #47965 is a reply to message #47963] |
Fri, 28 April 2017 19:31 |
omari
Messages: 276
Registered: March 2010
|
Experienced Member |
|
|
Hi,
Is it possible to add this function:
void Zero() { if(bp) Fill(bp, bp + alloc, (dword)0);}
And if possible ToString (I doubt of it's portability in BIG ENDIAN)
String Bits::ToString() const
{
String ss;
for(int i = alloc-1; i >= 0; i--)
ss << FormatIntHex(bp[i]);
return ss;
}
regards
omari.
|
|
|
|
|
|
|
|
| Re: Writing Bits object to disk [message #47991 is a reply to message #47390] |
Tue, 02 May 2017 22:54 |
crydev
Messages: 151
Registered: October 2012
Location: Netherlands
|
Experienced Member |
|
|
Hi Mirek,
I realized that my pipelined function was wrong. I made a silly mistake in the test case. The function is now fixed as:
// Testing pipelined version of Bits::Set(int, bool)
void Bits::PipelineSet(int i, const dword bs)
{
// Check whether i is within the bounds of the container.
ASSERT(i >= 0 && alloc >= 0);
// Get the DWORD index for the internal buffer.
int q = i >> 5;
// Get the bit index of the next available DWORD.
i &= 31;
// Do we need to expand the internal buffer first?
// Also check whether we can place 4 bits in the existing DWORD. If not, we should expand.
if(q >= alloc)
Expand(q);
// Get integer bit values according to existing DWORD value and indices.
// Assuming default value of bool is 0x1 if true!
const dword d1 = !!(bs & PowersOfTwo[0]) << i;
const dword d2 = !!(bs & PowersOfTwo[8]) << (i + 1);
const dword d3 = !!(bs & PowersOfTwo[16]) << (i + 2);
const dword d4 = !!(bs & PowersOfTwo[24]) << (i + 3);
bp[q] = (bp[q] | d1 | d2 | d3 | d4);
}
I did some more tests, and I am really surprised by the amount of difference the compiler and CPU make in this situation. I had to switch from my i7 2600k CPU to an Intel Core i7 4710MQ CPU because I was missing AVX2 (AVX2 really made it fast) When compiled with the Visual C++ compiler, I got the following result.
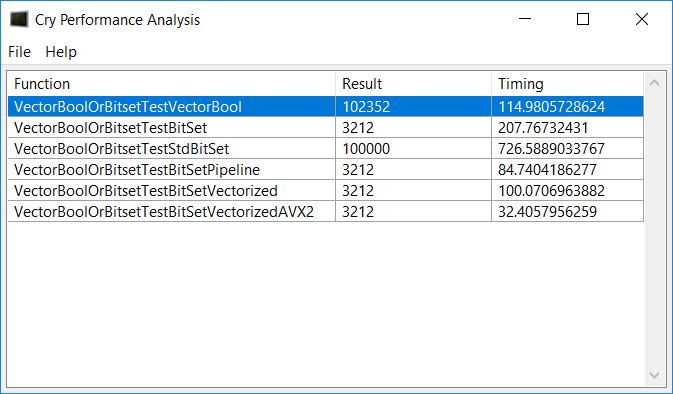
I was surprised to see how the newer CPU runs the simple pipelined version a lot faster than the 2600k! I also saw that a vectorized version of the Set function is almost simpler than the regular one. However, when I use the Intel C++ compiler, the results are very different:
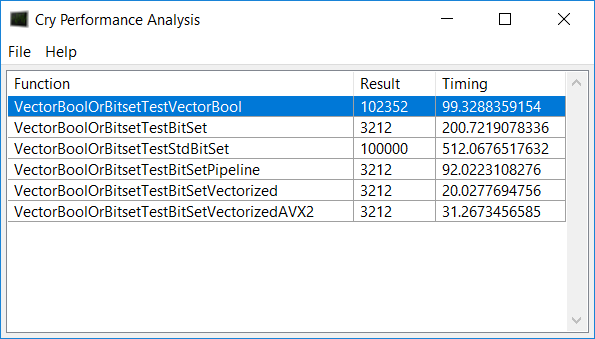
It seems that the Intel compiler generates way different code, making the SSE2 version blazingly fast. 10 times faster than the regular Set function. The strange thing is, that when I use the Visual C++ compiler, the timing of the different test cases is as I expected them to be. I expected the AVX2 function to be faster than the SSE2 one, which clearly is not the case with the Intel compiler.
The sources of my vectorized functions is as following:
// Testing vectorized version of Bits::Set(int, bool)
// We require that the input bools have value 0x80, e.g. most significant byte set if true.
void Bits::VectorSet(int i, const unsigned char vec[16])
{
// Check whether i is within the bounds of the container.
ASSERT(i >= 0 && alloc >= 0);
// Get the DWORD index for the internal buffer.
int q = i >> 5;
// Do we need to expand the internal buffer first?
if(q >= alloc)
Expand(q);
// Get the bit index of the next available DWORD.
i &= 31;
// Create a bitmask with vector intrinsics.
__m128i boolVec = _mm_set_epi8(vec[15], vec[14], vec[13], vec[12], vec[11], vec[10], vec[9], vec[8]
, vec[7], vec[6], vec[5], vec[4], vec[3], vec[2], vec[1], vec[0]);
const int bitMask = _mm_movemask_epi8(boolVec);
// Set the resulting WORD.
LowHighDword w;
w.dw = bp[q];
if (i == 16)
{
w.w2 = (short)bitMask;
}
else
{
w.w1 = (short)bitMask;
}
bp[q] = w.dw;
}
// The same vectorized function, but with AVX2 instructions.
void Bits::VectorSetAVX2(int i, const unsigned char vec[32])
{
// Check whether i is within the bounds of the container.
ASSERT(i >= 0 && alloc >= 0);
// Get the DWORD index for the internal buffer.
int q = i >> 5;
// Do we need to expand the internal buffer first?
if(q >= alloc)
Expand(q);
// Get the bit index of the next available DWORD.
i &= 31;
// Create a bitmask with vector intrinsics.
__m256i boolVec = _mm256_set_epi8(vec[31], vec[30], vec[29], vec[28], vec[27], vec[26], vec[25], vec[24], vec[23]
, vec[22], vec[21], vec[20], vec[19], vec[18], vec[17], vec[16], vec[15], vec[14], vec[13], vec[12], vec[11]
, vec[10], vec[9], vec[8], vec[7], vec[6], vec[5], vec[4], vec[3], vec[2], vec[1], vec[0]);
const int bitMask = _mm256_movemask_epi8(boolVec);
// Set the resulting DWORD.
bp[q] = bitMask;
}
Is it feasible to make a vectorized version for U++ by default, or should I provide it for myself?
Thanks,
evo
-
Attachment: Capture.PNG
(Size: 18.28KB, Downloaded 695 times)
-
Attachment: Capture2.PNG
(Size: 17.22KB, Downloaded 749 times)
|
|
|
|
| Re: Writing Bits object to disk [message #47992 is a reply to message #47991] |
Tue, 02 May 2017 23:55 |
|
mirek
Messages: 14285
Registered: November 2005
|
Ultimate Member |
|
|
crydev wrote on Tue, 02 May 2017 22:54Hi Mirek,
I realized that my pipelined function was wrong. I made a silly mistake in the test case. The function is now fixed as:
// Testing pipelined version of Bits::Set(int, bool)
void Bits::PipelineSet(int i, const dword bs)
{
// Check whether i is within the bounds of the container.
ASSERT(i >= 0 && alloc >= 0);
// Get the DWORD index for the internal buffer.
int q = i >> 5;
// Get the bit index of the next available DWORD.
i &= 31;
// Do we need to expand the internal buffer first?
// Also check whether we can place 4 bits in the existing DWORD. If not, we should expand.
if(q >= alloc)
Expand(q);
// Get integer bit values according to existing DWORD value and indices.
// Assuming default value of bool is 0x1 if true!
const dword d1 = !!(bs & PowersOfTwo[0]) << i;
const dword d2 = !!(bs & PowersOfTwo[8]) << (i + 1);
const dword d3 = !!(bs & PowersOfTwo[16]) << (i + 2);
const dword d4 = !!(bs & PowersOfTwo[24]) << (i + 3);
bp[q] = (bp[q] | d1 | d2 | d3 | d4);
}
I did some more tests, and I am really surprised by the amount of difference the compiler and CPU make in this situation. I had to switch from my i7 2600k CPU to an Intel Core i7 4710MQ CPU because I was missing AVX2 (AVX2 really made it fast) When compiled with the Visual C++ compiler, I got the following result.
I was surprised to see how the newer CPU runs the simple pipelined version a lot faster than the 2600k! I also saw that a vectorized version of the Set function is almost simpler than the regular one. However, when I use the Intel C++ compiler, the results are very different:
It seems that the Intel compiler generates way different code, making the SSE2 version blazingly fast. 10 times faster than the regular Set function. The strange thing is, that when I use the Visual C++ compiler, the timing of the different test cases is as I expected them to be. I expected the AVX2 function to be faster than the SSE2 one, which clearly is not the case with the Intel compiler.
The sources of my vectorized functions is as following:
// Testing vectorized version of Bits::Set(int, bool)
// We require that the input bools have value 0x80, e.g. most significant byte set if true.
void Bits::VectorSet(int i, const unsigned char vec[16])
{
// Check whether i is within the bounds of the container.
ASSERT(i >= 0 && alloc >= 0);
// Get the DWORD index for the internal buffer.
int q = i >> 5;
// Do we need to expand the internal buffer first?
if(q >= alloc)
Expand(q);
// Get the bit index of the next available DWORD.
i &= 31;
// Create a bitmask with vector intrinsics.
__m128i boolVec = _mm_set_epi8(vec[15], vec[14], vec[13], vec[12], vec[11], vec[10], vec[9], vec[8]
, vec[7], vec[6], vec[5], vec[4], vec[3], vec[2], vec[1], vec[0]);
const int bitMask = _mm_movemask_epi8(boolVec);
// Set the resulting WORD.
LowHighDword w;
w.dw = bp[q];
if (i == 16)
{
w.w2 = (short)bitMask;
}
else
{
w.w1 = (short)bitMask;
}
bp[q] = w.dw;
}
// The same vectorized function, but with AVX2 instructions.
void Bits::VectorSetAVX2(int i, const unsigned char vec[32])
{
// Check whether i is within the bounds of the container.
ASSERT(i >= 0 && alloc >= 0);
// Get the DWORD index for the internal buffer.
int q = i >> 5;
// Do we need to expand the internal buffer first?
if(q >= alloc)
Expand(q);
// Get the bit index of the next available DWORD.
i &= 31;
// Create a bitmask with vector intrinsics.
__m256i boolVec = _mm256_set_epi8(vec[31], vec[30], vec[29], vec[28], vec[27], vec[26], vec[25], vec[24], vec[23]
, vec[22], vec[21], vec[20], vec[19], vec[18], vec[17], vec[16], vec[15], vec[14], vec[13], vec[12], vec[11]
, vec[10], vec[9], vec[8], vec[7], vec[6], vec[5], vec[4], vec[3], vec[2], vec[1], vec[0]);
const int bitMask = _mm256_movemask_epi8(boolVec);
// Set the resulting DWORD.
bp[q] = bitMask;
}
Is it feasible to make a vectorized version for U++ by default, or should I provide it for myself?
Thanks,
evo
I still think there is a glitch somewhere benchmarking this. Would it possible to post a whole package here?
Mirek
|
|
|
|
|
|
| Re: Writing Bits object to disk [message #47996 is a reply to message #47995] |
Wed, 03 May 2017 09:53 |
|
mirek
Messages: 14285
Registered: November 2005
|
Ultimate Member |
|
|
crydev wrote on Wed, 03 May 2017 09:00mirek wrote on Tue, 02 May 2017 23:55
I still think there is a glitch somewhere benchmarking this. Would it possible to post a whole package here?
Mirek
The testing application is on Bitbucket here (only runs on Windows): https://bitbucket.org/evolution536/cry-performance-test
You still have to add the following functions to the Bits class:
void PipelineSet(int i, const dword bs);
void VectorSet(int i, const unsigned char vec[16]);
void VectorSetAVX2(int i, const unsigned char vec[32]);
crydev
Well, it is what I thought:
const int VectorBoolOrBitsetTestBitSetVectorized(Bits& buffer, const Vector<unsigned char>& randVec)
{
const int count = randVec.GetCount();
for (int i = 0; i < count; i += 16)
{
// Use the vectorized set method.
buffer.VectorSet(i, &randVec[i]);
}
int alloc = 0;
buffer.Raw(alloc);
return alloc;
}
This is not the proper benchmark. The large part of work is already done by grouping input bits into randVec, which is not included in the benchmark time IMO.
If you wanted the proper benchmark, you could e.g. set randVec to random values and then set bits in Bits for those values that satisfy some condition - that IMO will benchmark scenario closer to the real use. E.g. (for original Bits and random 0..100):
for(int i = 0; i < randValue.GetCount(); i++)
bits.Set(i, randValue[i] > 50);
[Updated on: Wed, 03 May 2017 09:55] Report message to a moderator |
|
|
|
| Re: Writing Bits object to disk [message #47998 is a reply to message #47996] |
Wed, 03 May 2017 11:12 |
crydev
Messages: 151
Registered: October 2012
Location: Netherlands
|
Experienced Member |
|
|
mirek wrote on Wed, 03 May 2017 09:53
Well, it is what I thought:
const int VectorBoolOrBitsetTestBitSetVectorized(Bits& buffer, const Vector<unsigned char>& randVec)
{
const int count = randVec.GetCount();
for (int i = 0; i < count; i += 16)
{
// Use the vectorized set method.
buffer.VectorSet(i, &randVec[i]);
}
int alloc = 0;
buffer.Raw(alloc);
return alloc;
}
This is not the proper benchmark. The large part of work is already done by grouping input bits into randVec, which is not included in the benchmark time IMO.
If you wanted the proper benchmark, you could e.g. set randVec to random values and then set bits in Bits for those values that satisfy some condition - that IMO will benchmark scenario closer to the real use. E.g. (for original Bits and random 0..100):
for(int i = 0; i < randValue.GetCount(); i++)
bits.Set(i, randValue[i] > 50);
Why is it the case? The random vector is precomputed, and the only thing both testing functions do is set the random values to the underlying Bits:
buffer.Set(i, rand[i]);
// vs.
buffer.VectorSet(i, &randVec[i]);
The problem is that the regular Set function only accepts one bool as parameter. The difference is that I can put a pointer to a buffer of bools directly into the Set function, which is exactly my use case (bulk set)
crydev
[Updated on: Wed, 03 May 2017 11:13] Report message to a moderator |
|
|
|
|
|
| Re: Writing Bits object to disk [message #48000 is a reply to message #47999] |
Wed, 03 May 2017 12:24 |
crydev
Messages: 151
Registered: October 2012
Location: Netherlands
|
Experienced Member |
|
|
mirek wrote on Wed, 03 May 2017 11:27crydev wrote on Wed, 03 May 2017 11:12
Why is it the case? The random vector is precomputed, and the only thing both testing functions do is set the random values to the underlying Bits:
Will you get that Vector<bool> (or bool *) for free in your app?
IMO, usual usage pattern will always be "check some condition, set the bit to result".
So the point I am trying to make is that with Bits, as they are, you are not required to "precompute" Vector<bool>. Which is why I think the benchmark is not telling the whole truth.
Mirek
I see what you mean! What test case would you propose? I implemented the Bits usage in my primary application again, and now with your changes, it finally starts to pay off using Bits instead. Also, thanks a lot for implementing the Raw and CreateRaw functions.
I'm still trying to get my own vectorized version working in the primary application. The setting indeed takes some overhead, but for now it seems to speed up the entire process (not just setting bits) by around 25%.
crydev
|
|
|
|
| Re: Writing Bits object to disk [message #48001 is a reply to message #48000] |
Wed, 03 May 2017 12:37 |
|
mirek
Messages: 14285
Registered: November 2005
|
Ultimate Member |
|
|
crydev wrote on Wed, 03 May 2017 12:24
I see what you mean! What test case would you propose? I implemented the Bits usage in my primary application again, and now with your changes, it finally starts to pay off using Bits instead. Also, thanks a lot for implementing the Raw and CreateRaw functions.
The one above... Set the primary array to Random(100), then sets bits to 1 to those >50. This of course will work without creating buffer single bit Set, but will require recomputing values into 0x0 / 0x80 buffer for vectorised version...
That said, I really am not opposed to vectorised version, I just do not think the interface is right. I would rather see something like
Set(int pos, bool b0, ...)
(varargs Set). That way it would be perhaps possible to work without precreating the buffer.
In either case, I think we should start with
Set(int pos, dword bits, int count);
|
|
|
|
| Re: Writing Bits object to disk [message #48002 is a reply to message #48001] |
Wed, 03 May 2017 18:33 |
crydev
Messages: 151
Registered: October 2012
Location: Netherlands
|
Experienced Member |
|
|
mirek wrote on Wed, 03 May 2017 12:37crydev wrote on Wed, 03 May 2017 12:24
I see what you mean! What test case would you propose? I implemented the Bits usage in my primary application again, and now with your changes, it finally starts to pay off using Bits instead. Also, thanks a lot for implementing the Raw and CreateRaw functions.
The one above... Set the primary array to Random(100), then sets bits to 1 to those >50. This of course will work without creating buffer single bit Set, but will require recomputing values into 0x0 / 0x80 buffer for vectorised version...
That said, I really am not opposed to vectorised version, I just do not think the interface is right. I would rather see something like
Set(int pos, bool b0, ...)
(varargs Set). That way it would be perhaps possible to work without precreating the buffer.
In either case, I think we should start with
Set(int pos, dword bits, int count);
I see. I made the 0x80 pre-computed buffer because in my use case, I have full control over what the input value is. Using 0x1 or 0x80 for a true value, will not require more work in my situation. However, I understand that you would not want such interface in U++.
I'll try to work out an example with such interface.
crydev
|
|
|
|
| Re: Writing Bits object to disk [message #48011 is a reply to message #48002] |
Sat, 06 May 2017 10:28 |
crydev
Messages: 151
Registered: October 2012
Location: Netherlands
|
Experienced Member |
|
|
Hi Mirek,
I worked out the test you suggested. The pipelined set function is not faster anymore. I can understand that this is the case. The SSE2 vectorized set function now is around 30% faster:
// Non naive vector test :D
const int VectorBoolOrBitsetTestBitSetVectorizedNonNaive(Bits& buffer, const Vector<unsigned char>& rand)
{
unsigned char vec[32];
const int count = rand.GetCount();
for (int i = 0; i < count; i += sizeof(vec))
{
for (int j = 0; j < sizeof(vec); ++j)
{
vec[j] = rand[i + j] > 50 ? 0x80 : 0x0;
}
// Use the vectorized set method.
buffer.VectorSetNonNaive(i, vec);
}
int alloc = 0;
buffer.Raw(alloc);
return alloc;
}
// The non naive vector set function, that actually implements only the vector
// setting, and not also the comparison of the input!
void Bits::VectorSetNonNaive(int i, const unsigned char vec[32])
{
// Check whether i is within the bounds of the container.
ASSERT(i >= 0 && alloc >= 0);
// Get the DWORD index for the internal buffer.
int q = i >> 5;
// Do we need to expand the internal buffer first?
if(q >= alloc)
Expand(q);
// Get the bit index of the next available DWORD.
i &= 31;
// Create a bitmask with vector intrinsics.
__m128i boolVecLow = _mm_load_si128((__m128i*)vec);
__m128i boolVecHigh = _mm_load_si128((__m128i*)(vec + 16));
const int bitMaskLow = _mm_movemask_epi8(boolVecLow);
const int bitMaskHigh = _mm_movemask_epi8(boolVecHigh);
// Set the resulting WORD.
LowHighDword w;
w.dw = bp[q];
w.w1 = (short)bitMaskLow;
w.w2 = (short)bitMaskHigh;
bp[q] = w.dw;
}
However, I was thinking: if I use vectorized code, I should be allowed to vectorize everything, including the comparison of the input values! I thought about my own use case (where I indeed also have to perform the kind of comparison you suggested), and I realized that this comparison could be vectorized. When I did so, the speeds of the SSE2 and AVX2 vectorized code examples skyrocketed. I understand that you may think of the vectorized comparison as a 'proof-of-concept' rather than a realistic implementation for U++, but I can actually utilize this implementation for my memory scanner. Besides, it was fun to write code like this. I am surprised how easy it can be done and how easily the game is played out.
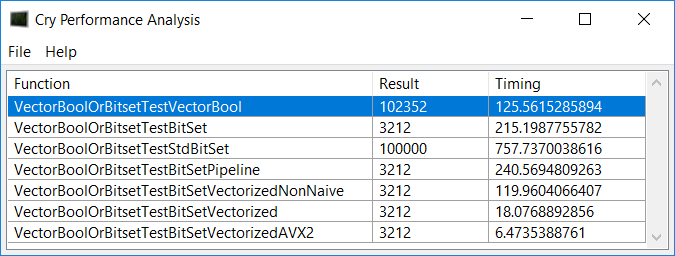
The source code is of the other tests is once again located at my Bitbucket repository: https://bitbucket.org/evolution536/cry-performance-test/src/ 212c3b4f51a29efa0e70841e76cceb11bcaacf06/VectorBoolOrBitsetT est.cpp?at=master&fileviewer=file-view-default
What do you think about a possible 'multi-set' implementation with an interface like:
void Set(int i, const Vector<bool>& vec, const int count);
Such function could contain a loop for a vector implementation, and the sequential Set function for the remainder. Maybe also a set function that allows you to manually prepare the dwords and have the set function solely manage the allocation and positioning for you.
crydev
-
Attachment: Capture.PNG
(Size: 18.52KB, Downloaded 661 times)
[Updated on: Sat, 06 May 2017 11:22] Report message to a moderator |
|
|
|
|
|
| Re: Writing Bits object to disk [message #48096 is a reply to message #48094] |
Tue, 16 May 2017 10:39 |
|
mirek
Messages: 14285
Registered: November 2005
|
Ultimate Member |
|
|
crydev wrote on Tue, 16 May 2017 09:12Hi Mirek,
How do you feel about adding a Bits::Set function that allows the user to put in packed bools? I was thinking about a function such as the following:
void Bits::VectorSet(int i, const dword bits32)
{
ASSERT(i >= 0 && alloc >= 0);
int q = i >> 5;
if(q >= alloc)
Expand(q);
i &= 31;
// Just place the input DWORD in position q in the Bits data buffer.
bp[q] = bits32;
}
Maybe with some checks, this is just an idea. I mean, this function works in my testcase because I only work with multiples of 32. Even though, this could be used as an assumption to make it fast. It accepts a bitset dword and directly sets it. This allows efficient use of the Bits structure while preparing the actual packed bools structure with SSE2 instructions like _mm_movemask_epi8.
Thanks!
crydev
I feel good about it, but I definitely think that it should be able to handle boundaries correctly...
I mean, this only works if i % 32 == 0. Should work in all other cases too, with variable number of bits.
[Updated on: Tue, 16 May 2017 10:42] Report message to a moderator |
|
|
|
| Re: Writing Bits object to disk [message #48097 is a reply to message #48094] |
Tue, 16 May 2017 13:12 |
|
mirek
Messages: 14285
Registered: November 2005
|
Ultimate Member |
|
|
Added these:
void Set(int i, dword bits, int count);
void Set64(int i, uint64 bits, int count);
void SetN(int i, int count, bool b = true);
Slight disadvantage is that while Set detects "aligned" operation (i % 32 == 0, count == 32), there is some penalty, but it seems to be quite small (about 3-4 opcodes). I guess if you want to be faster than that, you have to use Raw....
|
|
|
|
Goto Forum:
Current Time: Sun Jan 18 09:05:45 CET 2026
Total time taken to generate the page: 0.19057 seconds
|



 Members
Members Pages
Pages Help
Help Register
Register Login
Login Home
Home







")
